Employing cloud services can incur a great deal of risk if not planned and designed correctly. In fact, this is really no different than the challenges that are inherit within a single on-premises data center implementation. Power outages and network issues are common examples of challenges that can put your service — and your business — at risk.
For AWS cloud service, we have seen large-scale regional outages that are documented on the AWS Post-Event Summaries page. To gain a broader look at other cloud providers and services, the danluu/post-mortems repository provides a more holistic view of the cloud in general.
It’s time for service owners relying (or planning) on a single region to think hard about the best way to design resilient cloud services. While I will utilize AWS for this article, it is solely because of my level of expertise with the platform and not because one cloud platform should be considered better than another.
A Single-Region Approach Is Doomed to Fail
A cloud-based service implementation can be designed to leverage multiple availability zones. Think of availability zones as distinct locations within a specific region, but they are isolated from other availability zones in that region. Consider the following cloud-based service running on AWS inside the Kubernetes platform:
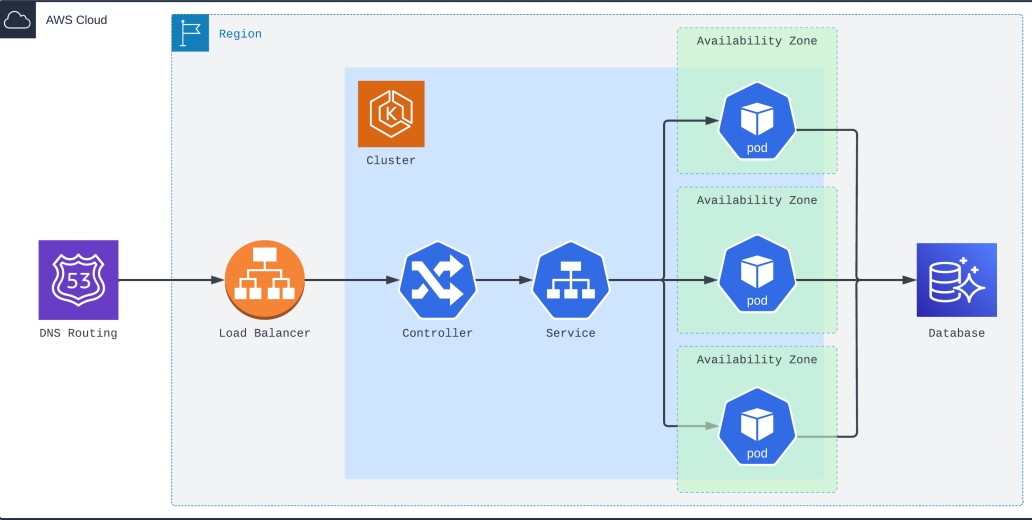
Figure 1: Cloud-based service utilizing Kubernetes with multiple availability zones
In Figure 1, inbound requests are handled by Route 53, arrive at a load balancer, and are directed to a Kubernetes cluster. The controller routes requests to the service that has three instances running, each in a different availability zone. For persistence, an Aurora Serverless database has been adopted.
While this design protects from the loss of one or two availability zones, the service is considered at risk when a region-wide outage occurs, similar to the AWS outage in the US-EAST-1 region on December 7th, 2021. A common mitigation strategy is to implement stand-by patterns that can become active when unexpected outages occur. However, these stand-by approaches can lead to bigger issues if they are not consistently participating by handling a portion of all requests.
Transitioning to More Than Two
With single-region services at risk, it’s important to understand how to best proceed. For that, we can draw upon the simple example of a trucking business. If you have a single driver who operates a single truck, your business is down when the truck or driver is unable to fulfill their duties. The immediate thought here is to add a second truck and driver. However, the better answer is to increase the fleet by two, which allows for an unexpected issue to complicate the original situation.
This is known as the “n + 2” rule, which becomes important when there are expectations set between you and your customers. For the trucking business, it might be a guaranteed delivery time. For your cloud-based service, it will likely be measured in service-level objectives (SLOs) and service-level agreements (SLAs).
It is common to set SLOs as four nines, meaning your service is operating as expected 99.99% of the time. This translates to the following error budgets, or down time, for the service:
- Month = 4 minutes and 21 seconds
- Week = 1 minute and 0.48 seconds
- Day = 8.6 seconds
If your SLAs include financial penalties, the importance of implementing the n + 2 rule becomes critical to making sure your services are available in the wake of an unexpected regional outage. Remember, that December 7, 2021 outage at AWS lasted more than eight hours.
The cloud-based service from Figure 1 can be expanded to employ a multi-region design:
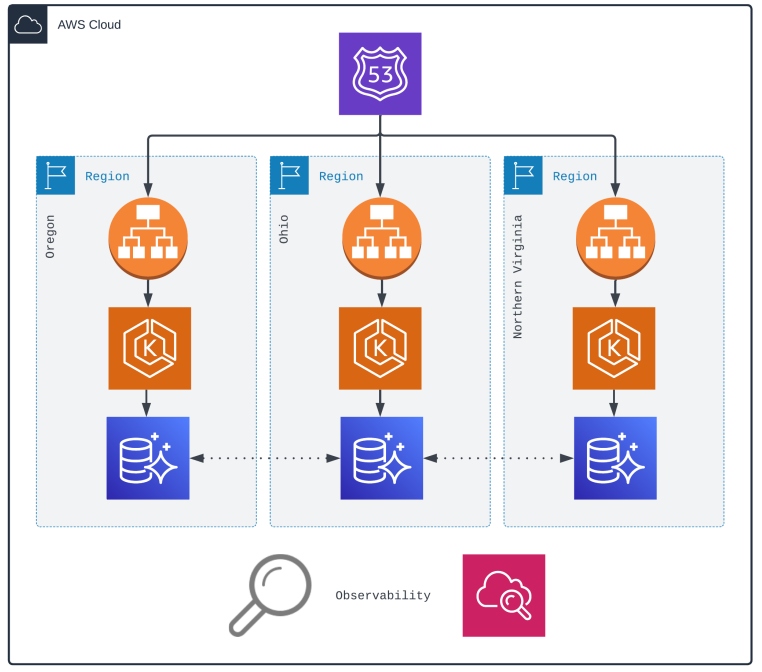
Figure 2: Multi-region cloud-based service utilizing Kubernetes and multiple availability zones
With a multi-region design, requests are handled by Route 53 but are directed to the best region to handle the request. The ambiguous term “best” is used intentionally, as the criteria could be based upon geographical proximity, least latency, or both. From there, the in-region Kubernetes cluster handles the request — still with three different availability zones.
Figure 2 also introduces the observability layer, which provides the ability to monitor cloud-based components and establish SLOs at the country and regional levels. This will be discussed in more detail shortly.
